 Learning
Learning

HuggingFace Transformers
Introduction¶
- Main NLP TASKS COURSE:
https://huggingface.co/course/chapter7/1?fw=pt
Working with pipelines¶
It connects a model with its necessary preprocessing and postprocessing steps, allowing us to directly input any text and get an intelligible answer:
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier("I've been waiting for a HuggingFace course my whole life.")
# [{'label': 'POSITIVE', 'score': 0.9598047137260437}]
it is also possible to pass batch of text.
the zero-shot classification pipeline lets you select the labels for classification.
using transformers we can perform many different operations:
- text classification
- zero-shot-classification
- text generation
- text completion (mask filling)
- token classification
- question answering
- summarization
- translation
Zero-shot classification¶
We’ll start by tackling a more challenging task where we need to classify texts that haven’t been labelled. This is a common scenario in real-world projects because annotating text is usually time-consuming and requires domain expertise. For this use case, the zero-shot-classification pipeline is very powerful: it allows you to specify which labels to use for the classification, so you don’t have to rely on the labels of the pretrained model. You’ve already seen how the model can classify a sentence as positive or negative using those two labels — but it can also classify the text using any other set of labels you like.
from transformers import pipeline
classifier = pipeline("zero-shot-classification")
classifier(
"This is a course about the Transformers library",
candidate_labels=["education", "politics", "business"],
)
# {'sequence': 'This is a course about the Transformers library',
# 'labels': ['education', 'business', 'politics'],
# 'scores': [0.8445963859558105, 0.111976258456707, 0.043427448719739914]}
Text-generation¶
from transformers import pipeline
generator = pipeline("text-generation", model="distilgpt2")
generator(
"In this course, we will teach you how to",
max_length=30,
num_return_sequences=2,
)
# [{'generated_text': 'In this course, we will teach you how to manipulate the world and '
# 'move your mental and physical capabilities to your advantage.'},
# {'generated_text': 'In this course, we will teach you how to become an expert and '
# 'practice realtime, and with a hands on experience on both real '
# 'time and real'}]
Mask-filling¶
The next pipeline you’ll try is fill-mask. The idea of this task is to fill in the blanks in a given text:
from transformers import pipeline
unmasker = pipeline("fill-mask")
unmasker("This course will teach you all about <mask> models.", top_k=2)
Named entity recognition¶
Named entity recognition (NER) is a task where the model has to find which parts of the input text correspond to entities such as persons, locations, or organizations. Let’s look at an example:
from transformers import pipeline
ner = pipeline("ner", grouped_entities=True)
ner("My name is Sylvain and I work at Hugging Face in Brooklyn.")
Question answering¶
The question-answering pipeline answers questions using information from a given context:
from transformers import pipeline
question_answerer = pipeline("question-answering")
question_answerer(
question="Where do I work?",
context="My name is Sylvain and I work at Hugging Face in Brooklyn",
)
# {'score': 0.6385916471481323, 'start': 33, 'end': 45, 'answer': 'Hugging Face'}
Note that this pipeline works by extracting information from the provided context; it does not generate the answer.
Language Models¶
All the Transformer models mentioned above (GPT, BERT, BART, T5, etc.) have been trained as language models. This means they have been trained on large amounts of raw text in a self-supervised fashion. Self-supervised learning is a type of training in which the objective is automatically computed from the inputs of the model. That means that humans are not needed to label the data!
This type of model develops a statistical understanding of the language it has been trained on, but it’s not very useful for specific practical tasks. Because of this, the general pretrained model then goes through a process called transfer learning.
During this process, the model is fine-tuned in a supervised way — that is, using human-annotated labels — on a given task.
An example of a task is predicting the next word in a sentence having read the n previous words. This is called causal language modeling because the output depends on the past and present inputs, but not the future ones. Another example is masked language modeling, in which the model predicts a masked word in the sentence.
Transformes are big models, apart from a few outliers (like DistilBERT), the general strategy to achieve better performance is by increasing the models’ sizes as well as the amount of data they are pretrained on.
Transfer Learning¶
the idea of transfer learning is to initialize the weights from an already trained model a fine tuning the last layer for our purposes. pretrained models are usually trained on very large amount of data and that is why they tend to work always better than models trained from scratch.
usually, transfer learning is applied by dropping the head of the pretrained model while keeping its body. Fine-tuning, on the other hand, is the training done after a model has been pretrained. To perform fine-tuning, you first acquire a pretrained language model, then perform additional training with a dataset specific to your task.
Transformers¶
Architectures introduction¶
The model is primarily composed of two blocks:
- Encoder: The encoder receives an input and builds a representation of it (its features). This means that the model is optimized to acquire understanding from the input.
Each of these parts can be used independently, depending on the task:
Encoder-only models: Good for tasks that require understanding of the input, such as sentence classification and named entity recognition.
Decoder-only models: Good for generative tasks such as text generation.
Encoder-decoder models or sequence-to-sequence models: Good for generative tasks that require an input, such as translation or summarization.
A key feature of Transformer models is that they are built with special layers called attention layers. all you need to know is that this layer will tell the model to pay specific attention to certain words in the sentence you passed it (and more or less ignore the others) when dealing with the representation of each word.
The same concept applies to any task associated with natural language: a word by itself has a meaning, but that meaning is deeply affected by the context, which can be any other word (or words) before or after the word being studied.
Architectures vs. checkpoints¶
As we dive into Transformer models in this course, you’ll see mentions of architectures and checkpoints as well as models. These terms all have slightly different meanings:
Architecture: This is the skeleton of the model — the definition of each layer and each operation that happens within the model. Checkpoints: These are the weights that will be loaded in a given architecture.
Encoder¶
The encoder outputs a numerical representation for each word used as input. the numerical representation is called Feature vector, it contains one vector per word (numerical representation), the dimension of the vector is defined by the architecture of the model itself.
Each word in the initial sequence affects every word's representation, they are contextual vectors. it does this thanks to the self-attention mechanism. The representation of the word is given by the others words in the prase.
encoders can use a standalone models and are particular good when we have to extract meaningful information, we are dealing with sequence classification, q&a and masked language modelling.
if we are dealing with masked language modelling to usage of encoders, with their bi-directional context, are very good in term of accuracy. They are also good in text-classification as sentiment analysis.
Encoder models use only the encoder of a Transformer model. At each stage, the attention layers can access all the words in the initial sentence. These models are often characterized as having “bi-directional” attention, and are often called auto-encoding models.
The pretraining of these models usually revolves around somehow corrupting a given sentence (for instance, by masking random words in it) and tasking the model with finding or reconstructing the initial sentence.
Encoder models are best suited for tasks requiring an understanding of the full sentence, such as sentence classification, named entity recognition (and more generally word classification), and extractive question answering. (ALBERT, BERT, DistilBERT, ELECTRA, RoBERTa)
Decoder¶
The decoder uses the encoder’s representation (features) along with other inputs to generate a target sequence. This means that the model is optimized for generating outputs.Decoder models use only the decoder of a Transformer model. At each stage, for a given word the attention layers can only access the words positioned before it in the sentence. These models are often called auto-regressive models.
The pretraining of decoder models usually revolves around predicting the next word in the sentence. These models are best suited for tasks involving text generation.
Encoder-Decoder¶
Encoder generates numerical representation of the text, in this case we pass direct the numerical representation of the encoder to the decoder as well with a start of sequence word.
the decoder decode the sequence a output a word. not as in an autoregressive model in combination with the representation of the encoder can used to generate a second word.
There is also the possibility to create an encoder-decoder assembling a custom encoder model and a decoder model
HuggingFace Models¶
looking at the sentiment analysis we have three stages: the tokenizer, then this output is given to the model and finally we generate the probability from the log-odds.
Tokenizer API¶
Like other neural networks, Transformer models can’t process raw text directly, so the first step of our pipeline is to convert the text inputs into numbers that the model can make sense of. To do this we use a tokenizer, which will be responsible for:
Splitting the input into words, subwords, or symbols (like punctuation) that are called tokens
Mapping each token to an integer
Adding additional inputs that may be useful to the model
All this preprocessing needs to be done in exactly the same way as when the model was pretrained, so we first need to download that information from the Model Hub. o do this, we use the AutoTokenizer class and its from_pretrained() method. Using the checkpoint name of our model, it will automatically fetch the data associated with the model’s tokenizer and cache it
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
Once we have the tokenizer, we can directly pass our sentences to it and we’ll get back a dictionary that’s ready to feed to our model! The only thing left to do is to convert the list of input IDs to tensors (Transformer models only accept tensors as input).
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt") #torch, tf for tensorflow
print(inputs)
"""
{
'input_ids': tensor([
[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102],
[ 101, 1045, 5223, 2023, 2061, 2172, 999, 102, 0, 0, 0, 0, 0, 0, 0, 0]
]),
'attention_mask': tensor([
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
])
}
"""
Going trough the model¶
We can download our pretrained model the same way we did with our tokenizer. 🤗 Transformers provides an AutoModel class which also has a from_pretrained() method:
from transformers import AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)
The vector output by the Transformer module is usually large. It generally has three dimensions:
Batch size: The number of sequences processed at a time (2 in our example).
Sequence length: The length of the numerical representation of the sequence (16 in our example).
Hidden size: The vector dimension of each model input. It is said to be “high dimensional” because of the last value. The hidden size can be very large (768 is common for smaller models, and in larger models this can reach 3072 or more).
outputs = model(**inputs)
print(outputs.last_hidden_state.shape)
#torch.Size([2, 16, 768])
AutoModelFor*¶
There are many different architectures available in 🤗 Transformers, with each one designed around tackling a specific task. Here is a non-exhaustive list:
Model (retrieve the hidden states)ForCausalLM ForMaskedLMForMultipleChoice ForQuestionAnsweringForSequenceClassification *ForTokenClassification
For our example, we will need a model with a sequence classification head (to be able to classify the sentences as positive or negative). So, we won’t actually use the AutoModel class, but AutoModelForSequenceClassification:
from transformers import AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
outputs = model(**inputs)
Models¶
The AutoModel class and all of its relatives are actually simple wrappers over the wide variety of models available in the library. It’s a clever wrapper as it can automatically guess the appropriate model architecture for your checkpoint, and then instantiates a model with this architecture.
Config and fresh models¶
we have to also care about the configuration of the model!
from transformers import BertConfig, BertModel
config = BertConfig() # Building the config
model = BertModel(config) # Building the model from the config
print(config)
# BertConfig {
# [...]
# "hidden_size": 768,
# "intermediate_size": 3072,
# "max_position_embeddings": 512,
# "num_attention_heads": 12,
# "num_hidden_layers": 12,
# [...]
# }
Load pretrained models¶
doing the operation above we are initiziationig the model with no pretrained weights! if instead we want that the models arrived pretrained we just have to specify it and giving the wanted checkpoint
from transformers import BertModel
model = BertModel.from_pretrained("bert-base-cased")
# we could replace BertModel with the equivalent AutoModel class.
This model is now initialized with all the weights of the checkpoint. It can be used directly for inference on the tasks it was trained on, and it can also be fine-tuned on a new task. By training with pretrained weights rather than from scratch, we can quickly achieve good results. The weights have been downloaded and cached (so future calls to the from_pretrained() method won’t re-download them) in the cache folder, which defaults to ~/.cache/huggingface/transformers. You can customize your cache folder by setting the HF_HOME environment variable.
Saving the model¶
to save the file just:
# Saving a model is as easy as loading one — we use the save_pretrained() method, which is analogous to the from_pretrained() method:
model.save_pretrained("directory_on_my_computer")
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import transformers
import torch
Tokenizer API¶
Tokenizer Techniques¶
it translate text into numbers, there are several possible approach to do this having the goal to encode the text while keeping as meaning as possible. we have at least three options:
Word-based tokenizer¶
The first type of tokenizer that comes to mind is word-based. It’s generally very easy to set up and use with only a few rules, and it often yields decent results. we basically split each sentence according to some criterion (spaces, punctuation).
There are also variations of word tokenizers that have extra rules for punctuation. With this kind of tokenizer, we can end up with some pretty large “vocabularies,” where a vocabulary is defined by the total number of independent tokens that we have in our corpus. Each word gets assigned an ID, starting from 0 and going up to the size of the vocabulary. The model uses these IDs to identify each word.
If we want to completely cover a language with a word-based tokenizer, we’ll need to have an identifier for each word in the language, which will generate a huge amount of tokens. For example, there are over 500,000 words in the English language, so to build a map from each word to an input ID we’d need to keep track of that many IDs. Finally, we need a custom token to represent words that are not in our vocabulary. This is known as the “unknown” token, often represented as ”[UNK]” or ””. It’s generally a bad sign if you see that the tokenizer is producing a lot of these tokens, as it wasn’t able to retrieve a sensible representation of a word and you’re losing information along the way.
Character-based¶
Character-based tokenizers split the text into characters, rather than words. This has two primary benefits: The vocabulary is much smaller.There are much fewer out-of-vocabulary (unknown) tokens, since every word can be built from characters. This approach isn’t perfect either. Since the representation is now based on characters rather than words, one could argue that, intuitively, it’s less meaningful: each character doesn’t mean a lot on its own, whereas that is the case with words. However, this again differs according to the language; in Chinese, for example, each character carries more information than a character in a Latin language.
Subword-based¶
Subword tokenization algorithms rely on the principle that frequently used words should not be split into smaller subwords, but rare words should be decomposed into meaningful subwords. For instance, “annoyingly” might be considered a rare word and could be decomposed into “annoying” and “ly”. These are both likely to appear more frequently as standalone subwords, while at the same time the meaning of “annoyingly” is kept by the composite meaning of “annoying” and “ly”.
Here is an example showing how a subword tokenization algorithm would tokenize the sequence “Let’s do tokenization!“:
let's</w> do</w> token ##ization</w> !</w>
These subwords end up providing a lot of semantic meaning: for instance, in the example above “tokenization” was split into “token” and “ization”, two tokens that have a semantic meaning while being space-efficient (only two tokens are needed to represent a long word). This allows us to have relatively good coverage with small vocabularies, and close to no unknown tokens.
subword based is the more robust approach. the idea is to finding a middle ground between word and character-based algorithm. They rely on the principle that frequently used words should not be split into smaller subwords, but rare words should be decomposed into meaningful subwords.
"Dog" will remain "dog" while "dogs" will becomes "dog" "s".
Unsurprisingly, there are many more techniques out there. To name a few:
- Byte-level BPE, as used in GPT-2
- WordPiece, as used in BERT
- SentencePiece or Unigram, as used in several multilingual models
Tokenizer Process¶
Loading and saving tokenizers is as simple as it is with models. Actually, it’s based on the same two methods: from_pretrained() and save_pretrained(). These methods will load or save the algorithm used by the tokenizer (a bit like the architecture of the model) as well as its vocabulary (a bit like the weights of the model).
Loading the BERT tokenizer trained with the same checkpoint as BERT is done the same way as loading the model, except we use the BertTokenizer class:
checkpoint = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
print(tokenizer("Using a Transformer network is simple"))
# tokenizer.save_pretrained("directory_on_my_computer")
{'input_ids': [101, 7993, 170, 13809, 23763, 2443, 1110, 3014, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
Overall Pipeline
first the text is splitted into tokes, then we add special tokens and lastly we transform it into the input IDS.
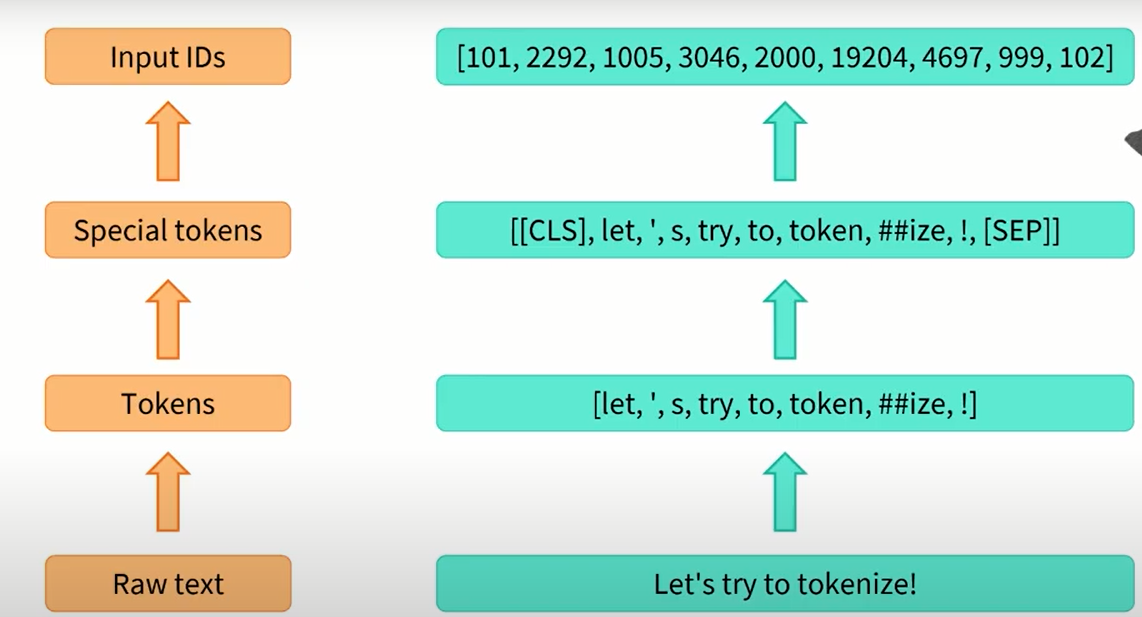
we can even perform this operation once at the time:
sequence = "Using a Transformer network is simple"
tokens = tokenizer.tokenize(sequence)
print(tokens)
['Using', 'a', 'Trans', '##former', 'network', 'is', 'simple']
# this tokenization is the output from ber-base-cased! changing that will also change the tokenization
input_ids = tokenizer.convert_tokens_to_ids(tokens)
print(input_ids) # are the mapping to the vocabulary (must be aware of there a related to a particular vocab)
[7993, 170, 13809, 23763, 2443, 1110, 3014]
final_inputs = tokenizer.prepare_for_model(input_ids)
print(final_inputs["input_ids"])
[101, 7993, 170, 13809, 23763, 2443, 1110, 3014, 102]
where 101 and 102 are special character added to indicate that are the beginning ant the end of the sentece passed. we can notice that there are two more charachters.
If we decode the sentence we can look what they are:
print(tokenizer.decode(final_inputs["input_ids"]))
[CLS] Using a Transformer network is simple [SEP]
Padding sentences¶
Batching allows the model to work when you feed it multiple sentences. Using multiple sequences is just as simple as building a batch with a single sequence. There’s a second issue, though. When you’re trying to batch together two (or more) sentences, they might be of different lengths. If you’ve ever worked with tensors before, you know that they need to be of rectangular shape, so you won’t be able to convert the list of input IDs into a tensor directly. To work around this problem, we usually pad the inputs.
In order to work around this, we’ll use padding to make our tensors have a rectangular shape. Padding makes sure all our sentences have the same length by adding a special word called the padding token to the sentences with fewer values. For example, if you have 10 sentences with 10 words and 1 sentence with 20 words, padding will ensure all the sentences have 20 words. In our example, the resulting tensor looks like this:
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequence1_ids = [[200, 200, 200]]
sequence2_ids = [[200, 200]]
batched_ids = [
[200, 200, 200],
[200, 200, tokenizer.pad_token_id],
]
print(model(torch.tensor(sequence1_ids)).logits)
print(model(torch.tensor(sequence2_ids)).logits)
print(model(torch.tensor(batched_ids)).logits)
Some weights of the model checkpoint at bert-base-cased were not used when initializing BertForSequenceClassification: ['cls.predictions.transform.LayerNorm.weight', 'cls.seq_relationship.bias', 'cls.seq_relationship.weight', 'cls.predictions.decoder.weight', 'cls.predictions.transform.dense.weight', 'cls.predictions.bias', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.transform.dense.bias'] - This IS expected if you are initializing BertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model). - This IS NOT expected if you are initializing BertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model). Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-cased and are newly initialized: ['classifier.bias', 'classifier.weight'] You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
tensor([[-0.4969, 0.1369]], grad_fn=<AddmmBackward0>)
tensor([[-0.4789, 0.1862]], grad_fn=<AddmmBackward0>)
tensor([[-0.4969, 0.1369],
[-0.6601, 0.0472]], grad_fn=<AddmmBackward0>)
There’s something wrong with the logits in our batched predictions: the second row should be the same as the logits for the second sentence, but we’ve got completely different values! This is because the key feature of Transformer models is attention layers that contextualize each token. These will take into account the padding tokens since they attend to all of the tokens of a sequence. To get the same result when passing individual sentences of different lengths through the model or when passing a batch with the same sentences and padding applied, we need to tell those attention layers to ignore the padding tokens. This is done by using an attention mask.
batched_ids = [
[200, 200, 200],
[200, 200, tokenizer.pad_token_id],
]
attention_mask = [
[1, 1, 1],
[1, 1, 0],
]
outputs = model(torch.tensor(batched_ids), attention_mask=torch.tensor(attention_mask))
print(outputs.logits)
tensor([[-0.4969, 0.1369],
[-0.4789, 0.1862]], grad_fn=<AddmmBackward0>)
# the padding can be done in several different ways:
# Will pad the sequences up to the maximum sequence length
sequences = ["Using a Transformer network is simple", "Using a Transformer network i", "Using a Transformer "]
model_inputs = tokenizer(sequences, padding="longest")
# Will pad the sequences up to the model max length
# (512 for BERT or DistilBERT)
model_inputs = tokenizer(sequences, padding="max_length")
# Will pad the sequences up to the specified max length
model_inputs = tokenizer(sequences, padding="max_length", max_length=8)
# Will truncate the sequences that are longer than the model max length
# (512 for BERT or DistilBERT)
model_inputs = tokenizer(sequences, truncation=True)
# Will truncate the sequences that are longer than the specified max length
model_inputs = tokenizer(sequences, max_length=8, truncation=True)
# wrapping up
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
tokens = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
output = model(**tokens)
Some weights of the model checkpoint at bert-base-cased were not used when initializing BertForSequenceClassification: ['cls.predictions.transform.LayerNorm.weight', 'cls.seq_relationship.bias', 'cls.seq_relationship.weight', 'cls.predictions.decoder.weight', 'cls.predictions.transform.dense.weight', 'cls.predictions.bias', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.transform.dense.bias'] - This IS expected if you are initializing BertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model). - This IS NOT expected if you are initializing BertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model). Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-cased and are newly initialized: ['classifier.bias', 'classifier.weight'] You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Longer sequences¶
With Transformer models, there is a limit to the lengths of the sequences we can pass the models. Most models handle sequences of up to 512 or 1024 tokens, and will crash when asked to process longer sequences. There are two solutions to this problem:
- Use a model with a longer supported sequence length.
- Truncate your sequences.
Models have different supported sequence lengths, and some specialize in handling very long sequences. Longformer is one example, and another is LED. If you’re working on a task that requires very long sequences, we recommend you take a look at those models.
https://huggingface.co/transformers/model_doc/longformer.html
Tokenizer-library¶
We have to create a new tokenizer if:
- New language
- New characters
- New domain
- New style
Training a tokenizer is not the same as training a model! Model training uses stochastic gradient descent to make the loss a little bit smaller for each batch. It’s randomized by nature (meaning you have to set some seeds to get the same results when doing the same training twice). Training a tokenizer is a statistical process that tries to identify which subwords are the best to pick for a given corpus, and the exact rules used to pick them depend on the tokenization algorithm. It’s deterministic, meaning you always get the same results when training with the same algorithm on the same corpus.
In order to train a new tokenizer we have to first of all collect a corpus of text then choose an architecture and train in.
from datasets import load_dataset
raw_datasets = load_dataset("code_search_net", "python")
# Using a Python generator, we can avoid Python loading anything into memory until it’s actually necessary.
# To create such a generator, you just to need to replace the brackets with parentheses:
def get_training_corpus():
return (raw_datasets["train"][i : i + 1000]["whole_func_string"] for i in range(0, len(raw_datasets["train"]), 1000))
# or better
def get_training_corpus():
dataset = raw_datasets["train"]
for start_idx in range(0, len(dataset), 1000):
samples = dataset[start_idx : start_idx + 1000]
yield samples["whole_func_string"]
training_corpus = get_training_corpus()
Even though we are going to train a new tokenizer, it’s a good idea to do this to avoid starting entirely from scratch. This way, we won’t have to specify anything about the tokenization algorithm or the special tokens we want to use; our new tokenizer will be exactly the same as GPT-2, and the only thing that will change is the vocabulary, which will be determined by the training on our corpus.
from transformers import AutoTokenizer
old_tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokenizer = old_tokenizer.train_new_from_iterator(training_corpus, 52000)
# 52000 is the corpus lenght!
# Note that AutoTokenizer.train_new_from_iterator() only works if the tokenizer you are using is a “fast” tokenizer.
tokenizer.save_pretrained("code-search-net-tokenizer")
we’ll first take a look at the preprocessing that each tokenizer applies to text. Here’s a high-level overview of the steps in the tokenization pipeline:
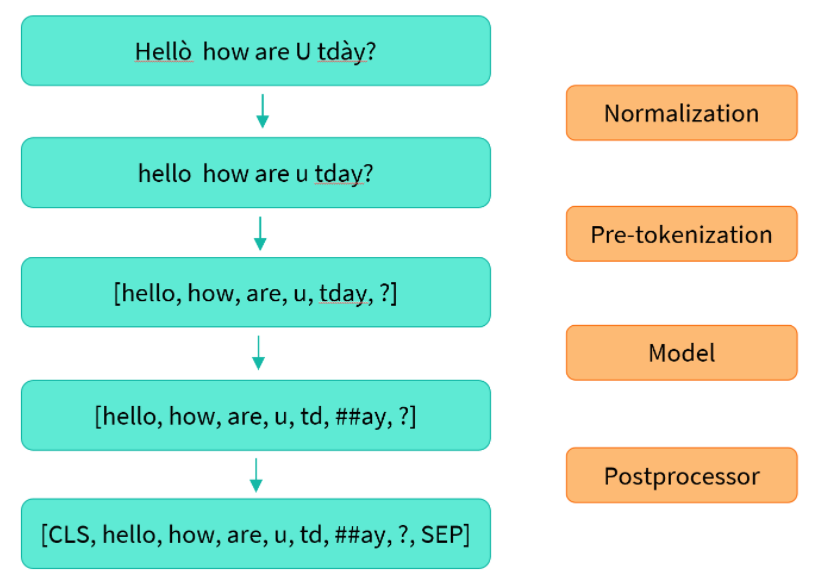
The normalization step involves some general cleanup, such as removing needless whitespace, lowercasing, and/or removing accents. If you’re familiar with Unicode normalization (such as NFC or NFKC), this is also something the tokenizer may apply.
# tokenizer = AutoTokenizerFast.from_pretrained("")
# text_normalized = tokenizer.backend_tokenizer.normalizer.normalize_str(text) # to check how this operation is performed!
# pre_tokenization = tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str("Hello, how are you?")
Datasets¶
How to load custom dataset¶
from datasets import load_dataset
# argument to pass to pandas.read_csv()
# data_files could also be a url
# csv
local_csv = load_dataset("csv", data_files="path-to-file.csv", sep=",")
# json single obj
local_csv = load_dataset("json", data_files="path-to-file.csv", field="data")
# json multiple files
data_files = {"train": f"{url}train.json", "test": f"{url}test-json"}
local_csv = load_dataset("json", data_files=data_files, field="data")
# train_test_split
dataset = squad.train_test_split(test_size = 0.1)
# select and shuffle
indices = [0,10,20,40, 15]
squad.shuffle().select(indices)
# filter the dataframe
squad_filtered = squad.filter(lambda x:x["title"].startswith("L"))
# flatten
squad.flatten()
# we have that answers is nested into text and answer_start, with flatten we bring them out ['answers.text', 'answers.answer_start'].
# map
def lower_case(ex):
return {"title": ex["title"].lower()}
squad_lower = squad.map(lower_case, batched=True)
## Using Dataset.map() with batched=True will be essential to unlock the speed of the “fast” tokenizers
# Renaming and filtering
drug_dataset = drug_dataset.filter(lambda x: x["condition"] is not None)
drug_dataset = drug_dataset.rename_column(original_column_name="Unnamed: 0", new_column_name="patient_id")
drug_dataset = drug_dataset.map(lowercase_condition)
# Create new columns
def compute_review_length(example):
return {"review_length": len(example["review"].split())}
drug_dataset = drug_dataset.map(compute_review_length)
# sort values
drug_dataset["train"].sort("review_length")[:3]
# removing emoji
drug_dataset = drug_dataset.map(lambda x: {"review": html.unescape(x["review"])})
Pandas integration¶
# convert into pandas dataframe!
dataset.set_format("pandas")
# easier way
dataset.to_pandas()
# back to original
dataset.reset_format()
# or
from datasets import Dataset
freq_dataset = Dataset.from_pandas(frequencies)
# create train-test-validation
drug_dataset_clean = drug_dataset["train"].train_test_split(train_size=0.8, seed=42)
# Rename the default "test" split to "validation"
drug_dataset_clean["validation"] = drug_dataset_clean.pop("test")
# Add the "test" set to our `DatasetDict`
drug_dataset_clean["test"] = drug_dataset["test"]
# save and load datasets
# arrow format
drug_dataset_clean.save_to_disk("path") # save
drug_arrow_load = load_from_disk("path") # load
# csv
for split, dataset in raw_dataset.items():
dataset.to_csv(f"myDataset-{split}.csv", index=None) #save
data_files = {"train": "myDataset-train.csv", "test": "myDataset-test.csv" }
load_dataset("csv", data_files=data_files)
from transformers import AdamW, AutoTokenizer, AutoModelForSequenceClassification
import torch
# Same as before
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
Huggingface datasets¶
We can use dataset from the huggingface Hub to fine tuning the model.
from datasets import load_dataset
raw_datasets = load_dataset("glue", "mrpc")
raw_datasets
Reusing dataset glue (/root/.cache/huggingface/datasets/glue/mrpc/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad)
DatasetDict({
train: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
validation: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 408
})
test: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 1725
})
})
# As you can see, we get a DatasetDict object which contains the training set,
# the validation set, and the test set. Each of those contains several columns
# (sentence1, sentence2, label, and idx) and a variable number of rows, which are
# the number of elements in each set (so, there are 3,668 pairs of sentences in
# the training set, 408 in the validation set, and 1,725 in the test set).
raw_train_dataset = raw_datasets["train"]
print(raw_train_dataset[0])
raw_train_dataset.features
{'sentence1': 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .', 'sentence2': 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .', 'label': 1, 'idx': 0}
{'idx': Value(dtype='int32', id=None),
'label': ClassLabel(num_classes=2, names=['not_equivalent', 'equivalent'], names_file=None, id=None),
'sentence1': Value(dtype='string', id=None),
'sentence2': Value(dtype='string', id=None)}
Dataset Processing¶
To keep the data as a dataset, we will use the Dataset.map() method. This also allows us some extra flexibility, if we need more preprocessing done than just tokenization.
def tokenize_wrapper(obs):
return tokenizer (
obs["sentence1"], obs["sentence2"], padding='max_length', truncation=True
)
tokenized_dataset = raw_datasets.map(tokenize_wrapper, batched=True)
print(tokenized_dataset.column_names)
tokenized_dataset = tokenized_dataset.remove_columns(["idx","sentence1", "sentence2"])
tokenized_dataset = tokenized_dataset.rename_column("label","labels")
tokenized_dataset = tokenized_dataset.with_format("torch")
tokenized_dataset
Loading cached processed dataset at /root/.cache/huggingface/datasets/glue/mrpc/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad/cache-99d1d2a4040377ab.arrow Loading cached processed dataset at /root/.cache/huggingface/datasets/glue/mrpc/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad/cache-0c0caf4c25019c57.arrow Loading cached processed dataset at /root/.cache/huggingface/datasets/glue/mrpc/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad/cache-dc680b012cb80bae.arrow
{'train': ['sentence1', 'sentence2', 'label', 'idx', 'input_ids', 'token_type_ids', 'attention_mask'], 'validation': ['sentence1', 'sentence2', 'label', 'idx', 'input_ids', 'token_type_ids', 'attention_mask'], 'test': ['sentence1', 'sentence2', 'label', 'idx', 'input_ids', 'token_type_ids', 'attention_mask']}
DatasetDict({
train: Dataset({
features: ['labels', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 3668
})
validation: Dataset({
features: ['labels', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 408
})
test: Dataset({
features: ['labels', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 1725
})
})
Dynamic Padding¶
as we have seen in the batch inputs together video, we need to pad senteces of different lenghts to make batches.
The first approach is to pad all the sentences in the whole dataset to the maximun length in the dataset. The main problem is that using this approach we are creating a lots of padding token.
Another way is to pad the sentences at the batch creation, to the length of the longest sentence, this is called dynamic padding. using this approach all the batches will have the smallest lenght possible but the main cons is that there are some instruments like TPU tat does not wprk so well with that.
The function that is responsible for putting together samples inside a batch is called a collate function. It’s an argument you can pass when you build a DataLoader, the default being a function that will just convert your samples to PyTorch tensors and concatenate them (recursively if your elements are lists, tuples, or dictionaries). This won’t be possible in our case since the inputs we have won’t all be of the same size. We have deliberately postponed the padding, to only apply it as necessary on each batch and avoid having over-long inputs with a lot of padding. To do this in practice, we have to define a collate function that will apply the correct amount of padding to the items of the dataset we want to batch together. Fortunately, the 🤗 Transformers library provides us with such a function via DataCollatorWithPadding. It takes a tokenizer when you instantiate it (to know which padding token to use, and whether the model expects padding to be on the left or on the right of the inputs) and will do everything you need:
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
samples = tokenized_dataset["train"][:8]
samples = {k: v for k, v in samples.items() if k not in ["idx", "sentence1", "sentence2"]}
[len(x) for x in samples["input_ids"]]
[512, 512, 512, 512, 512, 512, 512, 512]